Микроархитектура

Микроархитектура (иногда сокращается до µarch или uarch) — способ, которым данная архитектура набора команд реализована в процессоре.
Каждая архитектура набора команд может быть реализована с помощью различных микроархитектур[1]. Реализации могут варьироваться в зависимости от целей конкретной разработки или в результате технологических сдвигов[2].
Архитектура компьютера является комбинацией микроархитектуры, микрокода и архитектуры набора команд.
Связь с микрокодом и архитектурой набора команд
[править | править код]Архитектура набора команд — это приблизительно то же самое, что и модель программирования, с точки зрения программиста на языке ассемблера или создателя компилятора. Архитектура набора команд, в числе прочего, включает модель исполнения, регистры процессора, форматы адресов и данных, в то время, как микроархитектура включает составные части процессора и способы их взаимосвязи и взаимодействия для реализации архитектуры набора команд.
Однако во многих случаях работа элементов микроархитектуры контролируется микрокодом, встроенным в процессор. В случае наличия слоя микрокода в архитектуре процессора он выступает своеобразным интерпретатором, преобразуя команды уровня архитектуры набора команд в команды уровня микроархитектуры. При этом различные системы команд могут быть реализованы на базе одной микроархитектуры[3].
Микроархитектура машины обычно представляется в виде диаграмм определённой степени детализации, описывающие взаимосвязи различных микроархитектурных элементов, которые могут быть чем угодно: от отдельных вентилей и регистров до целых АЛУ и даже более крупных элементов. На этих диаграммах обычно выделяют тракт данных (где размещены данные) и тракт управления (который управляет движением данных)[4].
Машины с различной микроархитектурой могут иметь одинаковую архитектуру набора команд и, таким образом, быть пригодными для выполнения тех же программ. Новые микроархитектуры или схемотехнические решения вместе с прогрессом в полупроводниковой промышленности позволяют новым поколениям процессоров достигать более высокой производительности, используя ту же архитектуру набора команд.

-
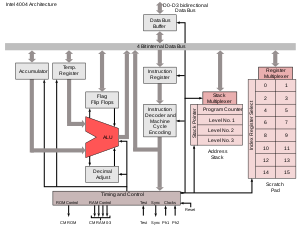 Блок-схема микроархитектуры первого в мире микропроцессора Intel 4004
Блок-схема микроархитектуры первого в мире микропроцессора Intel 4004 -
 Микроархитектура Intel 80286
Микроархитектура Intel 80286 -
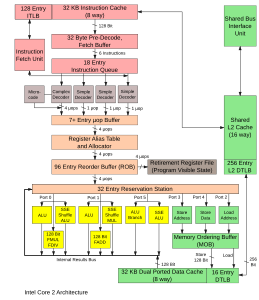 Микроархитектура Intel Core 2
Микроархитектура Intel Core 2



Аспекты микроархитектуры
[править | править код]Конвейерный тракт данных является наиболее широко используемым в современных микроархитектурах. Эта техника используется в большинстве современных микропроцессоров, микроконтроллеров и цифровых сигнальных процессоров. Конвейерная архитектура позволяет нескольким инструкциям перекрываться в исполнении, что напоминает сборочную линию. Конвейер включает несколько различных стадий, выбор которых является фундаментальным при разработке микроархитектуры.[4]
Некоторые из этих стадий включают выбор инструкций, декодирование инструкций, исполнение и запись результата. Некоторые архитектуры включают другие стадии, такие как доступ к памяти. Дизайн конвейера — один из центральных вопросов проектирования микроархитектуры.
Устройства исполнения также являются ключевыми для микроархитектуры. Они включают арифметико-логические устройства, устройства обработки чисел с плавающей точкой, устройства выборки и хранения, прогнозирование ветвления, параллелизм на уровне данных (SIMD). Эти блоки производят операции или вычисления процессора. Выбор числа блоков исполнения, их задержек, пропускной способности и способа соединения памяти с системой также являются микроархитектурными решениями.
Проектные решения уровня системы, такие как включать или нет периферийные устройства типа контроллеров памяти, могут считаться частью процесса разработки микроархитектуры, поскольку они содержат решения по уровню производительности и способам соединения этих периферийных устройств.
В отличие от архитектурного дизайна, где достижение определённого уровня производительности является главной целью, проектирование микроархитектуры уделяет большее внимание другим ограничениям. Поскольку дизайн микроархитектуры прямо влияет на то, что происходит в системе, внимание должно быть уделено следующим проблемам:
- площадь, стоимость чипа
- потребление энергии
- сложность логики
- простота соединений
- технологичность
- простота отладки
- тестируемость.
Концепции микроархитектуры
[править | править код]В общем случае, все ЦПУ, одночиповые микропроцессоры и многочиповые реализации выполняют программы, производя следующие шаги:
- Чтение инструкции и её декодирование
- Поиск всех связанных данных, необходимых для обработки инструкции
- Обработка инструкции
- Запись результатов
Эта последовательность выглядит просто, но осложняется тем фактом, что иерархия памяти (где располагаются инструкции и данные), которая включает в себя кэш, основную память и энергонезависимые устройства хранения, такие как жёсткие диски, всегда была медленнее самого процессора. Шаг (2) часто привносит длительные (по меркам ЦПУ) задержки, пока данные поступают по компьютерной шине. Значительная часть исследований посвящена разработкам, которые позволяют избегать таких задержек, насколько это возможно. В течение многих лет главной целью было выполнять больше инструкций параллельно, увеличивая таким образом эффективную скорость выполнения программ. Эти усилия вызывают усложнение логики и структуры схем. Изначально эти техники могли быть реализованы только на дорогих мейнфреймах и суперкомпьютерах вследствие большого объёма схем, необходимого для этого. По мере того, как полупроводниковая промышленность развивалась, всё большее количество этих техник могло быть реализовано в единственном полупроводниковом чипе.
Краткий обзор микроархитектурных концепций, распространённых в современных процессорах.
Выбор системы команд
[править | править код]За годы системы команд развились от изначально очень простых до иногда очень сложных (в определённых отношениях). В последнее время наиболее распространёнными становятся архитектуры RISC, VLIW , EPIC. Архитектуры, имеющие дело с параллелизмом на уровне данных, включают SIMD и векторные процессоры. Следует отметить, что многие используемые в этой области термины недостаточно содержательны. Особенно это касается «CISC»: многие ранние разработки, по традиции относимые к этому классу архитектуры системы команд, на практике гораздо проще современных RISC.
Однако выбор системы команд в значительной степени определяет сложность реализации высокопроизводительных устройств. Известной стратегией, использовавшейся при разработке первых RISC-процессоров, было упрощение инструкций до минимума индивидуальной семантической сложности в сочетании с высокой упорядоченностью и простотой кодирования. Такие единообразные инструкции просто извлекались, декодировались и исполнялись по принципу конвейера, позволяя реализовывать простую стратегию сокращения числа логических уровней для достижения более высоких частот функционирования. При этом кэш-память инструкций компенсировала естественно низкую плотность кода при высоких частотах работы, а большие наборы регистров использовались для исключения, насколько это возможно, обращений к (медленной) памяти.
Конвейеризация инструкций
[править | править код]Одна из первых и наиболее мощных техник повышения производительности — это использование конвейера инструкций. Ранние модели процессоров должны были выполнить все описанные выше шаги для одной инструкции, прежде чем перейти к следующей. Большие части схемы оставались неиспользуемыми на любом отдельном шаге. Например, часть схемы, осуществляющая декодирование инструкции, останется неиспользуемой во время её исполнения и так далее.
Конвейеры увеличивают производительность, позволяя нескольким инструкциям прокладывать свой путь через процессор в одно и то же время. В том же простом примере процессор начал бы декодировать (шаг 1) новую инструкцию, в то время как предыдущая ожидала бы результатов. В этом случае до четырёх инструкций могло находиться в обработке единовременно, позволяя процессору выглядеть в четыре раза быстрее. В то же время, любая отдельная инструкция выполняется в течение того же самого времени, поскольку существуют те же четыре шага, хотя в целом процессор выдаёт больше обработанных инструкций и может работать на значительно более высоких тактовых частотах.
RISC сделал конвейеры меньше и значительно проще в конструировании, отделив каждый этап обработки инструкций, зафиксировав длину машинной инструкции и сделав время их выполнения одинаковым — один такт или как максимум один цикл доступа к памяти (из-за выделения инструкций load и store). Процессор в целом функционирует на манер сборочной линии с инструкциями, поступающими с одной стороны и результатами, выходящими с другой. Из-за уменьшенной сложности классического RISC-конвейера, конвейерезированное ядро и кэш инструкций могли быть размещены на кристалле того же размера, который содержал бы лишь ядро в случае CISC-архитектуры. Это и было истинной причиной того, что RISC был быстрее. Ранние разработки, такие как SPARC и MIPS часто работали в 10 раз быстрее CISC-решений Intel и Motorola той же тактовой частоты и цены.
Конвейеры никоим образом не ограничиваются RISC-разработками. В 1986 году флагманская реализация VAX (VAX 8800) была сильно конвейеризирована, несколько опережая коммерческие реализации MIPS и SPARC. Большинство современных процессоров (даже встроенных) конвейеризированы, а процессоры с микрокодом но без конвейеров можно встретить только среди наиболее ограниченных по площади встроенных решений. Большие CISC машины, от VAX 8800 до современных Pentium 4 и Athlon используют как микрокод, так и конвейеры. Улучшения в конвейеризации и кэшировании — два важнейших микроархитектурных сдвига, позволяющих производительности процессоров идти в ногу со схемными технологиями, на которых они основаны.
Кэш
[править | править код]Когда улучшения в производстве чипов позволили размещать на кристалле ещё больше логики, начался поиск способов применения этого ресурса. Одним из направлений стало размещение прямо на кристалле чипа очень быстрой кэш памяти, доступ к которой происходил всего за несколько тактов процессора, в отличие от большого их количества при работе с основной памятью. При этом процессор также включал контроллер кэша, автоматизировавший чтение и запись данных в кэш.
RISC-процессоры стали снабжаться кэшем в середине-конце 1980-х (часто объёмом всего 4 КБ). Этот объём постоянно возрастал, и современные процессоры имеют по крайней мере 512 КБ, а наиболее мощные 1,2,4,6,8 и даже 12 МБ кэш-памяти, организованной в иерархию. В целом, больший объём кэша означает большую производительность вследствие меньшего времени простоя процессора.
Кэш-память и конвейеры хорошо дополняют друг друга. Если первоначально не имело смысл создавать конвейеры, работающие быстрее времени доступа к основной памяти, то с появлением кэша конвейер стал ограничен лишь более короткими задержками доступа к быстрой памяти на чипе. В итоге это позволяло увеличивать тактовые частоты процессоров.
Прогнозирование ветвления
[править | править код]Одно из препятствий в достижении более высокой производительности за счёт параллелизма на уровне данных возникает вследствие остановки и переполнения конвейера при ветвлениях. Обычно до конца неизвестно, будет ли выбрана ветвь условного ветвления в конвейере, поскольку ветвление зависит от результата, который берётся из регистра. С того времени, как декодер инструкций процессора выяснил, что натолкнулся на инструкцию, вызывающую ветвление до того, как определяющее решение значение может быть прочитано из регистра, конвейер необходимо остановить на несколько циклов. Если ветвь выбрана, то его нужно заполнить. Одновременно с ростом частоты процессоров увеличивалась глубина конвейеров и современные разработки имеют до 20 стадий. С учётом того, что в среднем каждая пятая инструкция вызывает ветвление, без дополнительных мер возникнет значительный простой.
Такие техники, как прогнозирование ветвлений и спекулятивное исполнение используются для уменьшения этих потерь.
Прогнозирование ветвления заключается в том, что оборудование делает обоснованное решение о том, какая из ветвей будет выбрана для исполнения. Современные разработки имеют достаточно сложные статистические системы прогнозирования, которые используют результаты последних ветвлений для предсказания будущих с большой точностью. Такие решения позволяют аппаратуре предварительно считать инструкции, не дожидаясь результата из регистра.
Спекулятивное исполнение — это дальнейшее развитие идеи, при котором инструкции из предсказанного пути не только считываются, но и исполняются до того, как становится точно известно, будет ли выбрана ветвь. Это помогает достичь высокой производительности, если решение было правильным, но вызывает риск большой потери времени, если решение ошибочно и инструкции нужно отменить.
Суперскалярность
[править | править код]Изначально, даже процессоры конвейерной микроархитектуры могли запускать только одну инструкцию в каждый момент времени. Очевидно, что программы могли бы выполняться быстрее, если запускать несколько инструкций одновременно. Именно этого достигают суперскалярные микроархитектуры за счёт использования нескольких одинаковых функциональных блоков, таких как АЛУ. Такие архитектуры появились когда на схеме стало возможно размещать больше элементов и к концу 1980-х они вышли на рынок.
В современных разработках часто можно видеть два устройства выборки, одно устройство хранения (многие инструкции не имеют результатов для хранения), два или более целочисленных АЛУ, два или более устройства обработки чисел с плавающей точкой, устройство SIMD и другие. Логика управления значительно усложнилась, обеспечивая чтение из памяти большого количества инструкций, распределение их по свободным функциональным блокам, сбор и упорядочение результатов.
Внеочередное исполнение
[править | править код]Появление кэшей сократило частоту и длительность простоев из-за ожидания чтения данных из иерархии памяти, но не устранило их совсем. В ранних разработках отсутствие данных в кэше вынуждало контроллер кэша остановить процессор и ожидать. Очевидно, что в программе почти всегда есть другие инструкции, данные для которых доступны в кэше в данный момент. Внеочередное исполнение позволяет выполнить эти инструкции в то время, как предыдущие ожидают данных из кэша. Затем результаты упорядочиваются так, что сохраняется предусмотренный в программе порядок. Эта техника также используется, чтобы избегать других остановок вследствие зависимых операндов, как в случае инструкций, ожидающих результатов длинных операций с плавающей точкой или других многоцикловых операций.
Переименование регистров
[править | править код]Переименование регистров — это техника, позволяющая избежать ненужного последовательного выполнения инструкций программы вследствие использования этими инструкциями одних и тех же регистров. Предположим, имеется две группы инструкций, использующих один регистр. Одна группа инструкций должна предшествовать другой для того, чтобы освободить этот регистр. Но если вторую группу инструкций перенаправить на другой однотипный регистр, то обе группы могут выполняться параллельно.
Многопроцессорность и многопоточность
[править | править код]В определённый период разработчики компьютеров оказались в тупике, связанном с растущим несоответствием между рабочими частотами ЦПУ и временем доступа к DRAM. Ни одна из технологий, эксплуатирующих параллелизм уровня инструкций внутри одной программы не могла компенсировать длительные остановки, возникающие когда данные должны быть прочитаны из основной памяти. К тому же, большое число транзисторов и высокие тактовые частоты, необходимые для более совершенных способов организации параллелизма инструкций, требовали таких уровней рассеивания тепла, что устройства нельзя было дёшево охлаждать. По этим причинам новые поколения компьютеров стали использовать более высокие уровни параллелизма, существовавшие вне одной программы или одного программного потока.
Эта тенденция также известна как вычисления с высокой пропускной способностью (en:High-throughput computing) и возникла в своё время на рынке мэйнфреймов, где OLTP требовала не столько высокой скорости обработки отдельной транзакции, сколько возможности обрабатывать большое их число одновременно. С распространением приложений, базирующихся на использовании транзакций, таких, как сетевая маршрутизация и обслуживание веб-сайтов, в компьютерной индустрии вновь появился акцент на ёмкости и пропускной способности.
Одним из способов достижения параллелизма такого вида являются многопроцессорные системы — компьютеры с несколькими ЦПУ. Когда-то ограничивавшиеся мэйнфреймами и суперкомпьютерами, многопроцессорные системы в виде миниатюрных (2-8)-процессорных серверов становятся[источник не указан 3629 дней] обычным явлением в малом бизнесе. Для крупных корпораций характерны масштабные мультипроцессоры (16-256). В 1990-е появились и многопроцессорные персональные компьютеры.
По мере дальнейшего уменьшения размера транзисторов (с соответствующим увеличением их числа в интегральных микросхемах) получали распространение многоядерные процессоры, у которых несколько физических процессорных ядер размещаются в единственном кремниевом чипе. Сначала такие решения предназначались для рынка встроенных систем, где более простые и компактные архитектуры позволяли разместить несколько экземпляров ЦПУ на одном кристалле. К 2005 году полупроводниковая технология позволила поместить в один корпус два высокопроизводительных универсальных процессора. В некоторых проектах, таких, как UltraSPARC T1 Sun Microsystems, разработчики вернулись к более простым микроархитектурам (скалярным с исполнением по порядку) с тем, чтобы разместить больше процессоров на одном кристалле.
Многопоточность является ещё одной технологией, получившей распространение сравнительно недавно[когда?]. Суть её в том, что когда процессору необходимо получить данные из медленной основной памяти, он вместо того, чтобы простаивать в ожидании этих данных, переключается на выполнение другого программного потока, который готов к исполнению. Не улучшая время выполнения отдельной программы, многопоточность тем не менее увеличивает пропускную способность всей системы. Концептуально операции многопоточного процессора эквивалентны переключению контекста (процесса или потока) на уровне операционной системы. Различие состоит в том, что многопоточный процессор производит переключение активного потока за один такт, в то время как программная реализация на уровне ОС требует на несколько порядков больших временных затрат. Это достигается путём аппаратной репликации регистрового контекста для каждого потока.
Дальнейшее развитие микроархитектур в этом направлении связано с одновременной многопоточностью. При этом суперскалярный процессор выполняет инструкции разных программ и потоков одновременно.
Примечания
[править | править код]- ↑ Miles Murdocca, Vincent Heuring. Computer Architecture and Organization, An Integrated Approach (англ.). — Wiley, 2007. — P. 151.
- ↑ Michael J. Flynn. Computer Architecture Pipelined and parallel Processor Design (англ.). — Jones and Bartlett[англ.], 2007. — P. 1—3.
- ↑ Andrew S. Tanenbaum. Structured Computer Organization (неопр.). — Fifth Edition. — 2007. — ISBN 0131485210.
- ↑ 1 2 John L. Hennessy and David A. Patterson. Computer Architecture: A Quantitative Approach (англ.). — Forth Edition. — Morgan Kaufmann Publishers, Inc, 2006. — ISBN 0123704901.
Статьи
[править | править код]- Евгений Музыченко. FAQ по процессоpам семейства x86. iXBT.com (24 февраля 2001). Дата обращения: 20 декабря 2016.
- Станислав Гарматюк. Современные десктопные процессоры архитектуры x86: общие принципы работы (x86 CPU FAQ 1.0). iXBT.com (9 февраля 2006). Дата обращения: 20 декабря 2016.
- Обзор микроархитектур современных десктопных процессоров, часть 1 (рус.)
- Обзор микроархитектур современных десктопных процессоров, часть 2 (рус.)
- Обзор микроархитектур современных десктопных процессоров, часть 3 (рус.)
- Эволюция микропроцессорных архитектур (рус.)
В статье есть список источников, но не хватает сносок. |
Технологии цифровых процессоров | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Архитектура | |||||||||
| Архитектура набора команд | |||||||||
| Машинное слово | |||||||||
| Параллелизм |
| ||||||||
| Реализации | |||||||||
| Компоненты | |||||||||
| Управление питанием | |||||||||