JH
| JH | |
|---|---|
| Разработчики | У Хунцзюнь (англ Wu Hongjun) |
| Опубликован | 16 января 2011 года |
| Размер хеша | 224, 256, 384, 512 |
| Число раундов | 42 |
JH — семейство из четырёх криптографических хеш-функций: JH-224, JH-256, JH-384 и JH-512.
Алгоритмы этих хеш-функций отличаются только значением одного внутреннего параметра — длины (в битах) выходного значения (которая и указана после дефиса в названии). Далее в статье при описании алгоритма я буду считать этот параметр частью входных данных для удобства, говоря о JH, как об одном алгоритме или одной хеш-функции.

Хеш-функция JH входит в пятёрку финалистов второго тура SHA-3. В процессе этого конкурса она была улучшена. В статье рассматривается последняя на данный момент версия, которую также можно назвать JH42 (так как главное изменение состояло в том, что число раундов в функции компрессии стало равно 42). Дата выхода документации по ней — 16 января 2011 года.
При хешировании входное сообщение дополняется и разделяется на части, которые далее последовательно обрабатываются так называемой функцией компрессии. Эта функция описана в спецификации в общем виде — то есть с переменным параметром d, меняя который можно конструировать JH-подобные хеш-функции (тем более криптостойкие, чем больше d). В JH исходно d=8.
При выборе финалиста в конкурсе SHA решающую роль играют не криптографические характеристики (они у всех функций отличные), а гибкость и оптимальность в программной и аппаратной реализации. На тему аппаратной реализации существует много исследований, например[1].
Алгоритм[2][править | править код]
Уточнения[править | править код]
О названии элементов битовых векторов[править | править код]
Будем считать, что у всех обсуждаемых тут битовых векторов есть начало и конец, причём бит, расположенный в начале (слева) является первым, имеет позицию 0 и считается наиболее значимым, соответственно, бит, расположенный в конце (справа), является последним, имеет позицию с наибольшим номером, на один меньшим, чем число разрядов вектора, и считается наименее значимым.
То же самое, за исключением номера позиции, будем подразумевать для векторов, состоящих из битовых векторов, например, для сообщения, состоящего из блоков, или блока, состоящего из полубайтов. С номером же позиции какой-либо составной части битового вектора, состоящей из нескольких бит, будет путаница, создаваемая для удобства. Так, номера позиций полубайтов в блоке будут начинаться с нуля, а номера позиций блоков в сообщении — с единицы…
В векторе
- 8afd4h
первый, наиболее значимый полубайт расположен слева – это 8; последний, наименее значимый полубайт расположен справа – это 4.
Если эту запись рассматривать, как битовый вектор, а не как полубайтовый, то она эквивалентна такой:
- 1000_1010_1111_1101_0100,
тут первый(с номером 0, левый, старший) бит - 1, а последний(с номером 19, правый, младший) - 0.
Обозначение конкатенации[править | править код]
Пусть вектор состоит из последовательно идущих векторов , тогда этот факт будет обозначаться так:



Используемые функции — обобщённый случай[править | править код]
Здесь описаны функции, с помощью которых можно строить JH-подобные алгоритмы, меняя параметр

S-box — Si(x)[править | править код]
Это функция, преобразующая s-блок (то есть размеры её входного и выходного значений одинаковы и равны 4 битам). В алгоритме используются 2 таких функции: и . Их таблицы значений такие:


| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
| 9 | 0 | 4 | b | d | c | 3 | f | 1 | a | 2 | 6 | 7 | 5 | 8 | e | |
| 3 | c | 6 | d | 5 | 7 | 1 | 9 | f | 2 | 0 | 4 | b | a | e | 8 |



Линейное преобразование пар ячеек — L(A,B)[править | править код]
Эта функция преобразует пару s-блоков (то есть размеры её входного и выходного значений одинаковы и равны 8 битам). Наиболее лаконичную запись она имеет в терминах конечных полей многочленов.
Рассмотрим конечное поле многочленов над степени не выше 3-й. Оно изоморфно полю ; установим стандартное для таких случаев соответствие межу полем многочленов и полем чисел: многочлен будет соответствовать числу, равному значению многочлена при . Выберем для этого поля многочленов следующий примитивный многочлен:



.

Тогда, если рассматривать , как функцию, преобразующую 2 многочлена, а числа и буквы — как многочлены, то

,

где «» и «» — операции умножения и сложения в данном поле многочленов.


Перемешивание — Pd[править | править код]
Функция является композицией трёх более простых перемешиваний, преобразующих массив из битовых векторов (то есть размеры их входных и выходных значений одинаковы и равны битам, где — число бит в одном элементе этого массива):





Приведем алгоритмы этих перемешиваний, обозначив за и (где и — битовые векторы одинакового размера для всех ) — входной и выходной векторы соответственно:





- :







- :




- :





Преобразование-раунд — Rd(A,C)[править | править код]
На вход подается - мерный вектор . Выход — - мерный вектор. Так же на вход подается -битная константа .


Вектор представляется в виде массива из полубайт: .
Потом над каждым полубайтом производится преобразование или в зависимости от значения (если , то , иначе — )


Далее над каждой парой вида производится линейное преобразование .


И в конце концов результаты опять группируются в вектор, биты которого подвергаются перемешиванию .
Это выражается в виде формулы:

Преобразование Ed[править | править код]
На входе — мерный вектор . Сначала происходит начальная группировка:
- :









Далее к результату этой группировки применяется преобразований-раундов с константами, изменяющимися от раунда к раунду. Начальное значение переменной задаётся, как целая часть числа , то есть




- :




Далее происходит конечная разгруппировка, обратная начальной:
- ,

Где

- :








Таким образом,


Функция свёртки Fd(H,M)[править | править код]
На входе -битный вектор и -битный вектор . Сначала преобразуется путём побитового сложения первой половины этого вектора с , потом над результатом выполняется преобразование и наконец результат преобразуется путём побитового сложения его второй половины с вектором .




Запишем это в виде формул. Пусть — первая (старшая) половина вектора , а — вторая. Пусть также функции и возвращают левую и правую половины соответственно. Тогда






Используемые функции — адаптация к аппаратной реализации при d=8[править | править код]
Конкретная реализация во многом зависит от таких параметров, как
- Желательное быстродействие
- Желательный размер
- Желательная технология
- Желательное энергопотребление
- Желательная помехоустойчивость
- Желательная стоимость
Поэтому без задания этих параметров адаптация невозможна. Я дам описание преобразования с помощью обычных для аппаратной разработки побитовых операций, а также некоторые константы, которые могут пригодиться, если нет существенного ограничения по размерам схемы.

Выражение преобразования L через простые операции с битами[править | править код]
Пусть , тогда









где «» — операция «исключающее или».

Пусть входной и выходной векторы lin_trans_in[0:7] и lin_trans_out[0:7] соответственно, тогда
assign
lin_trans_out[4:7]=lin_trans_in[4:7] ^ {lin_trans_in [1:3],lin_trans_in [0]} ^ {2'b0,lin_trans_in [0],1'b0},
lin_trans_out[0:3]=lin_trans_in[0:3] ^ {lin_trans_out[1:3],lin_trans_out[0]} ^ {2'b0,lin_trans_out[0],1'b0};
Константы H0 при разных lhash[править | править код]
Для будем иметь соответственно:

assign
hash_0_512[0:1023]= 1024'h6fd14b963e00aa17636a2e057a15d5438a225e8d0c97ef0be9341259f2b3c361891da0c1536f801e2aa9056bea2b6d80588eccdb2075baa6a90f3a76baf83bf70169e60541e34a6946b58a8e2e6fe65a1047a7d0c1843c243b6e71b12d5ac199cf57f6ec9db1f856a706887c5716b156e3c2fcdfe68517fb545a4678cc8cdd4b,
hash_0_384[0:1023]= 1024'h481e3bc6d813398a6d3b5e894ade879b63faea68d480ad2e3324cb21480f826798aec84d9082b928d45dea304111424936f555b2924847ecc72d0a93baf43ce1569b7f8a27db454c9ef4bd496397af0e589fc27d26aa80cd80c88b8c9deb2eda8a7981e8f8d5373af43967adddd17a71a9b4d3bda475d39497643fba9842737f,
hash_0_256[0:1023]= 1024'heb98a3412c20d3eb92cdbe7b9cb245c11c93519160d4c7fa260082d67e508a03a4239e267726b945e0fb1a48d41a9477cdb5ab26026b177a56f024420fff2fa871a396897f2e4d751d144908f77de262277695f776248f9487d5b6574780296c5c5e272dac8e0d6c518450c657057a0f7be4d367702412ea89e3ab13d31cd769,
hash_0_224[0:1023]= 1024'h2dfedd62f99a98acae7cacd619d634e7a4831005bc301216b86038c6c966149466d9899f2580706fce9ea31b1d9b1adc11e8325f7b366e10f994857f02fa06c11b4f1b5cd8c840b397f6a17f6e738099dcdf93a5adeaa3d3a431e8dec9539a6822b4a98aec86a1e4d574ac959ce56cf015960deab5ab2bbf9611dcf0dd64ea6e;
Константы C раундов R8[править | править код]

Представим их в виде массива, round_const[i][0:255]

assign
round_const[0 ][0:255]=256'h6a09e667f3bcc908b2fb1366ea957d3e3adec17512775099da2f590b0667322a,
round_const[1 ][0:255]=256'hbb896bf05955abcd5281828d66e7d99ac4203494f89bf12817deb43288712231,
round_const[2 ][0:255]=256'h1836e76b12d79c55118a1139d2417df52a2021225ff6350063d88e5f1f91631c,
round_const[3 ][0:255]=256'h263085a7000fa9c3317c6ca8ab65f7a7713cf4201060ce886af855a90d6a4eed,
round_const[4 ][0:255]=256'h1cebafd51a156aeb62a11fb3be2e14f60b7e48de85814270fd62e97614d7b441,
round_const[5 ][0:255]=256'he5564cb574f7e09c75e2e244929e9549279ab224a28e445d57185e7d7a09fdc1,
round_const[6 ][0:255]=256'h5820f0f0d764cff3a5552a5e41a82b9eff6ee0aa615773bb07e8603424c3cf8a,
round_const[7 ][0:255]=256'hb126fb741733c5bfcef6f43a62e8e5706a26656028aa897ec1ea4616ce8fd510,
round_const[8 ][0:255]=256'hdbf0de32bca77254bb4f562581a3bc991cf94f225652c27f14eae958ae6aa616,
round_const[9 ][0:255]=256'he6113be617f45f3de53cff03919a94c32c927b093ac8f23b47f7189aadb9bc67,
round_const[10][0:255]=256'h80d0d26052ca45d593ab5fb3102506390083afb5ffe107dacfcba7dbe601a12b,
round_const[11][0:255]=256'h43af1c76126714dfa950c368787c81ae3beecf956c85c962086ae16e40ebb0b4,
round_const[12][0:255]=256'h9aee8994d2d74a5cdb7b1ef294eed5c1520724dd8ed58c92d3f0e174b0c32045,
round_const[13][0:255]=256'h0b2aa58ceb3bdb9e1eef66b376e0c565d5d8fe7bacb8da866f859ac521f3d571,
round_const[14][0:255]=256'h7a1523ef3d970a3a9b0b4d610e02749d37b8d57c1885fe4206a7f338e8356866,
round_const[15][0:255]=256'h2c2db8f7876685f2cd9a2e0ddb64c9d5bf13905371fc39e0fa86e1477234a297,
round_const[16][0:255]=256'h9df085eb2544ebf62b50686a71e6e828dfed9dbe0b106c9452ceddff3d138990,
round_const[17][0:255]=256'he6e5c42cb2d460c9d6e4791a1681bb2e222e54558eb78d5244e217d1bfcf5058,
round_const[18][0:255]=256'h8f1f57e44e126210f00763ff57da208a5093b8ff7947534a4c260a17642f72b2,
round_const[19][0:255]=256'hae4ef4792ea148608cf116cb2bff66e8fc74811266cd641112cd17801ed38b59,
round_const[20][0:255]=256'h91a744efbf68b192d0549b608bdb3191fc12a0e83543cec5f882250b244f78e4,
round_const[21][0:255]=256'h4b5d27d3368f9c17d4b2a2b216c7e74e7714d2cc03e1e44588cd9936de74357c,
round_const[22][0:255]=256'h0ea17cafb8286131bda9e3757b3610aa3f77a6d0575053fc926eea7e237df289,
round_const[23][0:255]=256'h848af9f57eb1a616e2c342c8cea528b8a95a5d16d9d87be9bb3784d0c351c32b,
round_const[24][0:255]=256'hc0435cc3654fb85dd9335ba91ac3dbde1f85d567d7ad16f9de6e009bca3f95b5,
round_const[25][0:255]=256'h927547fe5e5e45e2fe99f1651ea1cbf097dc3a3d40ddd21cee260543c288ec6b,
round_const[26][0:255]=256'hc117a3770d3a34469d50dfa7db020300d306a365374fa828c8b780ee1b9d7a34,
round_const[27][0:255]=256'h8ff2178ae2dbe5e872fac789a34bc228debf54a882743caad14f3a550fdbe68f,
round_const[28][0:255]=256'habd06c52ed58ff091205d0f627574c8cbc1fe7cf79210f5a2286f6e23a27efa0,
round_const[29][0:255]=256'h631f4acb8d3ca4253e301849f157571d3211b6c1045347befb7c77df3c6ca7bd,
round_const[30][0:255]=256'hae88f2342c23344590be2014fab4f179fd4bf7c90db14fa4018fcce689d2127b,
round_const[31][0:255]=256'h93b89385546d71379fe41c39bc602e8b7c8b2f78ee914d1f0af0d437a189a8a4,
round_const[32][0:255]=256'h1d1e036abeef3f44848cd76ef6baa889fcec56cd7967eb909a464bfc23c72435,
round_const[33][0:255]=256'ha8e4ede4c5fe5e88d4fb192e0a0821e935ba145bbfc59c2508282755a5df53a5,
round_const[34][0:255]=256'h8e4e37a3b970f079ae9d22a499a714c875760273f74a9398995d32c05027d810,
round_const[35][0:255]=256'h61cfa42792f93b9fde36eb163e978709fafa7616ec3c7dad0135806c3d91a21b,
round_const[36][0:255]=256'hf037c5d91623288b7d0302c1b941b72676a943b372659dcd7d6ef408a11b40c0,
round_const[37][0:255]=256'h2a306354ca3ea90b0e97eaebcea0a6d7c6522399e885c613de824922c892c490,
round_const[38][0:255]=256'h3ca6cdd788a5bdc5ef2dceeb16bca31e0a0d2c7e9921b6f71d33e25dd2f3cf53,
round_const[39][0:255]=256'hf72578721db56bf8f49538b0ae6ea470c2fb1339dd26333f135f7def45376ec0,
round_const[40][0:255]=256'he449a03eab359e34095f8b4b55cd7ac7c0ec6510f2c4cc79fa6b1fee6b18c59e,
round_const[41][0:255]=256'h73bd6978c59f2b219449b36770fb313fbe2da28f6b04275f071a1b193dde2072;
Позиции полубайтов после перемешивания P8[править | править код]
Пусть на вход поступил 1024-битный вектор — массив из 256-ти 4-битных векторов: , а на выходе имеем , тогда . Это означает, что первый полубайт выходного вектора будет равен полубайту входного вектора с номером позиции (от 0 до 255), содержащемся в первом байте константы permut_pose[0:2047], второй полубайт выходного вектора — полубайту входного вектора с номером позиции, содержащемся во втором байте permut_pose[0:2047], и т. д.



![{\displaystyle B_{i}=A_{permut\_pose[i*8-1-:8]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4d36409683c3a4c4d9d5eb5a0cac4ef64366b9ea)
assign
permut_pose[0:2047]=2048'h00030407080b0c0f10131417181b1c1f20232427282b2c2f30333437383b3c3f40434447484b4c4f50535457585b5c5f60636467686b6c6f70737477787b7c7f80838487888b8c8f90939497989b9c9fa0a3a4a7a8abacafb0b3b4b7b8bbbcbfc0c3c4c7c8cbcccfd0d3d4d7d8dbdcdfe0e3e4e7e8ebeceff0f3f4f7f8fbfcff020106050a090e0d121116151a191e1d222126252a292e2d323136353a393e3d424146454a494e4d525156555a595e5d626166656a696e6d727176757a797e7d828186858a898e8d929196959a999e9da2a1a6a5aaa9aeadb2b1b6b5bab9bebdc2c1c6c5cac9cecdd2d1d6d5dad9dedde2e1e6e5eae9eeedf2f1f6f5faf9fefd;
Используемые функции — адаптация к программной реализации при d=8[править | править код]
Суть этой адаптации заключается в минимизации числа операций путём использования операций с как можно более длинными операндами. Сделать это позволяют такие технологии, как, например, SIMD, SSE2, AVX.
примеры реализации на языке C[править | править код]
Для пояснения работы функций, а также для того, чтобы показать константы раундов, будут приводиться куски кода на C[3]. Будучи соединёнными в один файл и дополненными функцией main(), приведённой ниже, они компилируются[4]; полученная программа реализует функцию .

#include <emmintrin.h>
#include <stdlib.h>
#include <stdio.h>
typedef __m128i word128; /*word128 defines a 128-bit SSE2 word*/
/*define data alignment for different C compilers*/
#if defined(__GNUC__)
#define DATA_ALIGN16(x) x __attribute__ ((aligned(16)))
#else
#define DATA_ALIGN16(x) __declspec(align(16)) x
#endif
/*The following defines operations on 128-bit word(s)*/
#define CONSTANT(b) _mm_set1_epi8((b)) /*set each byte in a 128-bit register to be "b"*/
#define XOR(x,y) _mm_xor_si128((x),(y)) /*XOR(x,y) = x ^ y, where x and y are two 128-bit word*/
#define AND(x,y) _mm_and_si128((x),(y)) /*AND(x,y) = x & y, where x and y are two 128-bit word*/
#define ANDNOT(x,y) _mm_andnot_si128((x),(y)) /*ANDNOT(x,y) = (!x) & y, where x and y are two 128-bit word*/
#define OR(x,y) _mm_or_si128((x),(y)) /*OR(x,y) = x | y, where x and y are two 128-bit word*/
#define SHR1(x) _mm_srli_epi16((x), 1) /*SHR1(x) = x >> 1, where x is a 128 bit word*/
#define SHR2(x) _mm_srli_epi16((x), 2) /*SHR2(x) = x >> 2, where x is a 128 bit word*/
#define SHR4(x) _mm_srli_epi16((x), 4) /*SHR4(x) = x >> 4, where x is a 128 bit word*/
#define SHR8(x) _mm_slli_epi16((x), 8) /*SHR8(x) = x >> 8, where x is a 128 bit word*/
#define SHR16(x) _mm_slli_epi32((x), 16) /*SHR16(x) = x >> 16, where x is a 128 bit word*/
#define SHR32(x) _mm_slli_epi64((x), 32) /*SHR32(x) = x >> 32, where x is a 128 bit word*/
#define SHR64(x) _mm_slli_si128((x), 8) /*SHR64(x) = x >> 64, where x is a 128 bit word*/
#define SHL1(x) _mm_slli_epi16((x), 1) /*SHL1(x) = x << 1, where x is a 128 bit word*/
#define SHL2(x) _mm_slli_epi16((x), 2) /*SHL2(x) = x << 2, where x is a 128 bit word*/
#define SHL4(x) _mm_slli_epi16((x), 4) /*SHL4(x) = x << 4, where x is a 128 bit word*/
#define SHL8(x) _mm_srli_epi16((x), 8) /*SHL8(x) = x << 8, where x is a 128 bit word*/
#define SHL16(x) _mm_srli_epi32((x), 16) /*SHL16(x) = x << 16, where x is a 128 bit word*/
#define SHL32(x) _mm_srli_epi64((x), 32) /*SHL32(x) = x << 32, where x is a 128 bit word*/
#define SHL64(x) _mm_srli_si128((x), 8) /*SHL64(x) = x << 64, where x is a 128 bit word*/
int main()
{
int j;
void* e8_out;
//here can be any constant you like to use for E8 check
char e8_in[128]={0,0xe0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
e8_out=(void*)calloc(9,sizeof(word128));
//16 byte allignment - important!
e8_out=(void*)(((int) e8_out) + 16 - (((int) e8_out) & 15));
for (j = 0; j < 128; j++)
*((char*)e8_out+j)=e8_in[j];
printf("\ninput\n");
for (j = 0; j < 128; j++)
printf("%.2x",(char)(*((char*)e8_out+j)) & 0xff);
E8((word128*)e8_out);
//out must be equal
//2dfedd62f99a98acae7cacd619d634e7a4831005bc301216b86038c6c966149466d9899f2580706fce9ea31b1d9b1adc11e8325f7b366e10f994857f02fa06c11b4f1b5cd8c840b397f6a17f6e738099dcdf93a5adeaa3d3a431e8dec9539a6822b4a98aec86a1e4d574ac959ce56cf015960deab5ab2bbf9611dcf0dd64ea6e
printf("\noutput\n");
for (j = 0; j < 128; j++)
printf("%.2x",(char)(*((char*)e8_out+j)) & 0xff);
return(0);
}
Функция SBox[править | править код]
Преобразует четыре 128-битных вектора в зависимости от 128-битной константы. То есть

Алгоритм таков. Введём ещё 128-битную переменную t и проинициализируем переменные начальными значениями
,

тогда последовательность присваиваний следующая:











/*Sbox implements S0 and S1, selected by a constant bit*/
#define S_BOX(m0,m1,m2,m3,cnst) { \
word128 t; \
m3 = XOR(m3,CONSTANT(0xff)); \
m0 = XOR(m0,ANDNOT(m2,cnst)); \
t = XOR(cnst,AND(m0,m1)); \
m0 = XOR(m0,AND(m3,m2)); \
m3 = XOR(m3,ANDNOT(m1,m2)); \
m1 = XOR(m1,AND(m0,m2)); \
m2 = XOR(m2,ANDNOT(m3,m0)); \
m0 = XOR(m0,OR(m1,m3)); \
m3 = XOR(m3,AND(m1,m2)); \
m2 = XOR(m2,t); \
m1 = XOR(m1,AND(t,m0)); \
}
- описание используемых макросов см. в блоке "предварительные объявления на C"
Функция LinTrans[править | править код]
Преобразует восемь 128-битных переменных. Пусть , тогда









/*The MDS code*/
#define LIN_TRANS(word) \
word[1] = XOR(word[1],word[2]); \
word[3] = XOR(word[3],word[4]); \
word[5] = XOR(XOR(word[5],word[6]),word[0]); \
word[7] = XOR(word[7],word[0]); \
word[0] = XOR(word[0],word[3]); \
word[2] = XOR(word[2],word[5]); \
word[4] = XOR(XOR(word[4],word[7]),word[1]); \
word[6] = XOR(word[6],word[1]);
В коде для удобства дальнейшего использования соответствует (word[0],word[2],word[4],word[6],word[1],word[3],word[5],word[7])

- описание используемых макросов см. в блоке "предварительные объявления на C"
Функция Permutation[править | править код]
Преобразует 128-битную переменную в зависимости от целой константы . Эта функция не оптимизируется для использования 128-битных переменных, однако для совместного использования с другими функциями из этого раздела она необходима.

Пусть , где. Алгоритм получения числа таков:



- :



Здесь запись означает такой участок алгоритма, после которого переменная принимает значение, которое было у переменной , а переменная принимает значение, которое было у переменной .



/*The following defines operations on 128-bit word(s)*/
#define SWAP0(x) OR(SHR1(AND((x),CONSTANT(0xaa))),SHL1(AND((x),CONSTANT(0x55)))) /*swapping bit 2i with bit 2i+1 of the 128-bit x */
#define SWAP1(x) OR(SHR2(AND((x),CONSTANT(0xcc))),SHL2(AND((x),CONSTANT(0x33)))) /*swapping bit 4i||4i+1 with bit 4i+2||4i+3 of the 128-bit x */
#define SWAP2(x) OR(SHR4(AND((x),CONSTANT(0xf0))),SHL4(AND((x),CONSTANT(0xf)))) /*swapping bits 8i||8i+1||8i+2||8i+3 with bits 8i+4||8i+5||8i+6||8i+7 of the 128-bit x */
#define SWAP3(x) OR(SHR8(x),SHL8(x)) /*swapping bits 16i||16i+1||...||16i+7 with bits 16i+8||16i+9||...||16i+15 of the 128-bit x */
#define SWAP4(x) OR(SHR16(x),SHL16(x)) /*swapping bits 32i||32i+1||...||32i+15 with bits 32i+16||32i+17||...||32i+31 of the 128-bit x */
#define SWAP5(x) _mm_shuffle_epi32((x),_MM_SHUFFLE(2,3,0,1)) /*swapping bits 64i||64i+1||...||64i+31 with bits 64i+32||64i+33||...||64i+63 of the 128-bit x*/
#define SWAP6(x) _mm_shuffle_epi32((x),_MM_SHUFFLE(1,0,3,2)) /*swapping bits 128i||128i+1||...||128i+63 with bits 128i+64||128i+65||...||128i+127 of the 128-bit x*/
#define STORE(x,p) _mm_store_si128((__m128i *)(p), (x)) /*store the 128-bit word x into memeory address p, where p is the multile of 16 bytes*/
#define LOAD(p) _mm_load_si128((__m128i *)(p)) /*load 16 bytes from the memory address p, return a 128-bit word, where p is the multile of 16 bytes*/
#define PERMUTATION(word,n) \
word[1] = SWAP##n(word[1]); word[3] = SWAP##n(word[3]); word[5] = SWAP##n(word[5]); word[7] = SWAP##n(word[7]);
- описание используемых макросов см. в блоке «предварительные объявления на C»
Функция E8, адаптированная к программной реализации[править | править код]
Преобразует 1024-битный вектор. Совпадает с функцией , описанной в обобщённом случае (в том смысле, что при совпадении значений аргументов совпадают значения функций). Пусть на вход поступил 1024-битный вектор. Представим его в виде набора 8-ми 128-битных переменных: . После следующих преобразований они будут представлять собой выходной вектор:









Использующиеся 128-битные константы задаются следующим образом:

/*42 round constants, each round constant is 32-byte (256-bit)*/
DATA_ALIGN16(const unsigned char E8_bitslice_roundconstant[42][32])={
{0x72,0xd5,0xde,0xa2,0xdf,0x15,0xf8,0x67,0x7b,0x84,0x15,0xa,0xb7,0x23,0x15,0x57,0x81,0xab,0xd6,0x90,0x4d,0x5a,0x87,0xf6,0x4e,0x9f,0x4f,0xc5,0xc3,0xd1,0x2b,0x40},
{0xea,0x98,0x3a,0xe0,0x5c,0x45,0xfa,0x9c,0x3,0xc5,0xd2,0x99,0x66,0xb2,0x99,0x9a,0x66,0x2,0x96,0xb4,0xf2,0xbb,0x53,0x8a,0xb5,0x56,0x14,0x1a,0x88,0xdb,0xa2,0x31},
{0x3,0xa3,0x5a,0x5c,0x9a,0x19,0xe,0xdb,0x40,0x3f,0xb2,0xa,0x87,0xc1,0x44,0x10,0x1c,0x5,0x19,0x80,0x84,0x9e,0x95,0x1d,0x6f,0x33,0xeb,0xad,0x5e,0xe7,0xcd,0xdc},
{0x10,0xba,0x13,0x92,0x2,0xbf,0x6b,0x41,0xdc,0x78,0x65,0x15,0xf7,0xbb,0x27,0xd0,0xa,0x2c,0x81,0x39,0x37,0xaa,0x78,0x50,0x3f,0x1a,0xbf,0xd2,0x41,0x0,0x91,0xd3},
{0x42,0x2d,0x5a,0xd,0xf6,0xcc,0x7e,0x90,0xdd,0x62,0x9f,0x9c,0x92,0xc0,0x97,0xce,0x18,0x5c,0xa7,0xb,0xc7,0x2b,0x44,0xac,0xd1,0xdf,0x65,0xd6,0x63,0xc6,0xfc,0x23},
{0x97,0x6e,0x6c,0x3,0x9e,0xe0,0xb8,0x1a,0x21,0x5,0x45,0x7e,0x44,0x6c,0xec,0xa8,0xee,0xf1,0x3,0xbb,0x5d,0x8e,0x61,0xfa,0xfd,0x96,0x97,0xb2,0x94,0x83,0x81,0x97},
{0x4a,0x8e,0x85,0x37,0xdb,0x3,0x30,0x2f,0x2a,0x67,0x8d,0x2d,0xfb,0x9f,0x6a,0x95,0x8a,0xfe,0x73,0x81,0xf8,0xb8,0x69,0x6c,0x8a,0xc7,0x72,0x46,0xc0,0x7f,0x42,0x14},
{0xc5,0xf4,0x15,0x8f,0xbd,0xc7,0x5e,0xc4,0x75,0x44,0x6f,0xa7,0x8f,0x11,0xbb,0x80,0x52,0xde,0x75,0xb7,0xae,0xe4,0x88,0xbc,0x82,0xb8,0x0,0x1e,0x98,0xa6,0xa3,0xf4},
{0x8e,0xf4,0x8f,0x33,0xa9,0xa3,0x63,0x15,0xaa,0x5f,0x56,0x24,0xd5,0xb7,0xf9,0x89,0xb6,0xf1,0xed,0x20,0x7c,0x5a,0xe0,0xfd,0x36,0xca,0xe9,0x5a,0x6,0x42,0x2c,0x36},
{0xce,0x29,0x35,0x43,0x4e,0xfe,0x98,0x3d,0x53,0x3a,0xf9,0x74,0x73,0x9a,0x4b,0xa7,0xd0,0xf5,0x1f,0x59,0x6f,0x4e,0x81,0x86,0xe,0x9d,0xad,0x81,0xaf,0xd8,0x5a,0x9f},
{0xa7,0x5,0x6,0x67,0xee,0x34,0x62,0x6a,0x8b,0xb,0x28,0xbe,0x6e,0xb9,0x17,0x27,0x47,0x74,0x7,0x26,0xc6,0x80,0x10,0x3f,0xe0,0xa0,0x7e,0x6f,0xc6,0x7e,0x48,0x7b},
{0xd,0x55,0xa,0xa5,0x4a,0xf8,0xa4,0xc0,0x91,0xe3,0xe7,0x9f,0x97,0x8e,0xf1,0x9e,0x86,0x76,0x72,0x81,0x50,0x60,0x8d,0xd4,0x7e,0x9e,0x5a,0x41,0xf3,0xe5,0xb0,0x62},
{0xfc,0x9f,0x1f,0xec,0x40,0x54,0x20,0x7a,0xe3,0xe4,0x1a,0x0,0xce,0xf4,0xc9,0x84,0x4f,0xd7,0x94,0xf5,0x9d,0xfa,0x95,0xd8,0x55,0x2e,0x7e,0x11,0x24,0xc3,0x54,0xa5},
{0x5b,0xdf,0x72,0x28,0xbd,0xfe,0x6e,0x28,0x78,0xf5,0x7f,0xe2,0xf,0xa5,0xc4,0xb2,0x5,0x89,0x7c,0xef,0xee,0x49,0xd3,0x2e,0x44,0x7e,0x93,0x85,0xeb,0x28,0x59,0x7f},
{0x70,0x5f,0x69,0x37,0xb3,0x24,0x31,0x4a,0x5e,0x86,0x28,0xf1,0x1d,0xd6,0xe4,0x65,0xc7,0x1b,0x77,0x4,0x51,0xb9,0x20,0xe7,0x74,0xfe,0x43,0xe8,0x23,0xd4,0x87,0x8a},
{0x7d,0x29,0xe8,0xa3,0x92,0x76,0x94,0xf2,0xdd,0xcb,0x7a,0x9,0x9b,0x30,0xd9,0xc1,0x1d,0x1b,0x30,0xfb,0x5b,0xdc,0x1b,0xe0,0xda,0x24,0x49,0x4f,0xf2,0x9c,0x82,0xbf},
{0xa4,0xe7,0xba,0x31,0xb4,0x70,0xbf,0xff,0xd,0x32,0x44,0x5,0xde,0xf8,0xbc,0x48,0x3b,0xae,0xfc,0x32,0x53,0xbb,0xd3,0x39,0x45,0x9f,0xc3,0xc1,0xe0,0x29,0x8b,0xa0},
{0xe5,0xc9,0x5,0xfd,0xf7,0xae,0x9,0xf,0x94,0x70,0x34,0x12,0x42,0x90,0xf1,0x34,0xa2,0x71,0xb7,0x1,0xe3,0x44,0xed,0x95,0xe9,0x3b,0x8e,0x36,0x4f,0x2f,0x98,0x4a},
{0x88,0x40,0x1d,0x63,0xa0,0x6c,0xf6,0x15,0x47,0xc1,0x44,0x4b,0x87,0x52,0xaf,0xff,0x7e,0xbb,0x4a,0xf1,0xe2,0xa,0xc6,0x30,0x46,0x70,0xb6,0xc5,0xcc,0x6e,0x8c,0xe6},
{0xa4,0xd5,0xa4,0x56,0xbd,0x4f,0xca,0x0,0xda,0x9d,0x84,0x4b,0xc8,0x3e,0x18,0xae,0x73,0x57,0xce,0x45,0x30,0x64,0xd1,0xad,0xe8,0xa6,0xce,0x68,0x14,0x5c,0x25,0x67},
{0xa3,0xda,0x8c,0xf2,0xcb,0xe,0xe1,0x16,0x33,0xe9,0x6,0x58,0x9a,0x94,0x99,0x9a,0x1f,0x60,0xb2,0x20,0xc2,0x6f,0x84,0x7b,0xd1,0xce,0xac,0x7f,0xa0,0xd1,0x85,0x18},
{0x32,0x59,0x5b,0xa1,0x8d,0xdd,0x19,0xd3,0x50,0x9a,0x1c,0xc0,0xaa,0xa5,0xb4,0x46,0x9f,0x3d,0x63,0x67,0xe4,0x4,0x6b,0xba,0xf6,0xca,0x19,0xab,0xb,0x56,0xee,0x7e},
{0x1f,0xb1,0x79,0xea,0xa9,0x28,0x21,0x74,0xe9,0xbd,0xf7,0x35,0x3b,0x36,0x51,0xee,0x1d,0x57,0xac,0x5a,0x75,0x50,0xd3,0x76,0x3a,0x46,0xc2,0xfe,0xa3,0x7d,0x70,0x1},
{0xf7,0x35,0xc1,0xaf,0x98,0xa4,0xd8,0x42,0x78,0xed,0xec,0x20,0x9e,0x6b,0x67,0x79,0x41,0x83,0x63,0x15,0xea,0x3a,0xdb,0xa8,0xfa,0xc3,0x3b,0x4d,0x32,0x83,0x2c,0x83},
{0xa7,0x40,0x3b,0x1f,0x1c,0x27,0x47,0xf3,0x59,0x40,0xf0,0x34,0xb7,0x2d,0x76,0x9a,0xe7,0x3e,0x4e,0x6c,0xd2,0x21,0x4f,0xfd,0xb8,0xfd,0x8d,0x39,0xdc,0x57,0x59,0xef},
{0x8d,0x9b,0xc,0x49,0x2b,0x49,0xeb,0xda,0x5b,0xa2,0xd7,0x49,0x68,0xf3,0x70,0xd,0x7d,0x3b,0xae,0xd0,0x7a,0x8d,0x55,0x84,0xf5,0xa5,0xe9,0xf0,0xe4,0xf8,0x8e,0x65},
{0xa0,0xb8,0xa2,0xf4,0x36,0x10,0x3b,0x53,0xc,0xa8,0x7,0x9e,0x75,0x3e,0xec,0x5a,0x91,0x68,0x94,0x92,0x56,0xe8,0x88,0x4f,0x5b,0xb0,0x5c,0x55,0xf8,0xba,0xbc,0x4c},
{0xe3,0xbb,0x3b,0x99,0xf3,0x87,0x94,0x7b,0x75,0xda,0xf4,0xd6,0x72,0x6b,0x1c,0x5d,0x64,0xae,0xac,0x28,0xdc,0x34,0xb3,0x6d,0x6c,0x34,0xa5,0x50,0xb8,0x28,0xdb,0x71},
{0xf8,0x61,0xe2,0xf2,0x10,0x8d,0x51,0x2a,0xe3,0xdb,0x64,0x33,0x59,0xdd,0x75,0xfc,0x1c,0xac,0xbc,0xf1,0x43,0xce,0x3f,0xa2,0x67,0xbb,0xd1,0x3c,0x2,0xe8,0x43,0xb0},
{0x33,0xa,0x5b,0xca,0x88,0x29,0xa1,0x75,0x7f,0x34,0x19,0x4d,0xb4,0x16,0x53,0x5c,0x92,0x3b,0x94,0xc3,0xe,0x79,0x4d,0x1e,0x79,0x74,0x75,0xd7,0xb6,0xee,0xaf,0x3f},
{0xea,0xa8,0xd4,0xf7,0xbe,0x1a,0x39,0x21,0x5c,0xf4,0x7e,0x9,0x4c,0x23,0x27,0x51,0x26,0xa3,0x24,0x53,0xba,0x32,0x3c,0xd2,0x44,0xa3,0x17,0x4a,0x6d,0xa6,0xd5,0xad},
{0xb5,0x1d,0x3e,0xa6,0xaf,0xf2,0xc9,0x8,0x83,0x59,0x3d,0x98,0x91,0x6b,0x3c,0x56,0x4c,0xf8,0x7c,0xa1,0x72,0x86,0x60,0x4d,0x46,0xe2,0x3e,0xcc,0x8,0x6e,0xc7,0xf6},
{0x2f,0x98,0x33,0xb3,0xb1,0xbc,0x76,0x5e,0x2b,0xd6,0x66,0xa5,0xef,0xc4,0xe6,0x2a,0x6,0xf4,0xb6,0xe8,0xbe,0xc1,0xd4,0x36,0x74,0xee,0x82,0x15,0xbc,0xef,0x21,0x63},
{0xfd,0xc1,0x4e,0xd,0xf4,0x53,0xc9,0x69,0xa7,0x7d,0x5a,0xc4,0x6,0x58,0x58,0x26,0x7e,0xc1,0x14,0x16,0x6,0xe0,0xfa,0x16,0x7e,0x90,0xaf,0x3d,0x28,0x63,0x9d,0x3f},
{0xd2,0xc9,0xf2,0xe3,0x0,0x9b,0xd2,0xc,0x5f,0xaa,0xce,0x30,0xb7,0xd4,0xc,0x30,0x74,0x2a,0x51,0x16,0xf2,0xe0,0x32,0x98,0xd,0xeb,0x30,0xd8,0xe3,0xce,0xf8,0x9a},
{0x4b,0xc5,0x9e,0x7b,0xb5,0xf1,0x79,0x92,0xff,0x51,0xe6,0x6e,0x4,0x86,0x68,0xd3,0x9b,0x23,0x4d,0x57,0xe6,0x96,0x67,0x31,0xcc,0xe6,0xa6,0xf3,0x17,0xa,0x75,0x5},
{0xb1,0x76,0x81,0xd9,0x13,0x32,0x6c,0xce,0x3c,0x17,0x52,0x84,0xf8,0x5,0xa2,0x62,0xf4,0x2b,0xcb,0xb3,0x78,0x47,0x15,0x47,0xff,0x46,0x54,0x82,0x23,0x93,0x6a,0x48},
{0x38,0xdf,0x58,0x7,0x4e,0x5e,0x65,0x65,0xf2,0xfc,0x7c,0x89,0xfc,0x86,0x50,0x8e,0x31,0x70,0x2e,0x44,0xd0,0xb,0xca,0x86,0xf0,0x40,0x9,0xa2,0x30,0x78,0x47,0x4e},
{0x65,0xa0,0xee,0x39,0xd1,0xf7,0x38,0x83,0xf7,0x5e,0xe9,0x37,0xe4,0x2c,0x3a,0xbd,0x21,0x97,0xb2,0x26,0x1,0x13,0xf8,0x6f,0xa3,0x44,0xed,0xd1,0xef,0x9f,0xde,0xe7},
{0x8b,0xa0,0xdf,0x15,0x76,0x25,0x92,0xd9,0x3c,0x85,0xf7,0xf6,0x12,0xdc,0x42,0xbe,0xd8,0xa7,0xec,0x7c,0xab,0x27,0xb0,0x7e,0x53,0x8d,0x7d,0xda,0xaa,0x3e,0xa8,0xde},
{0xaa,0x25,0xce,0x93,0xbd,0x2,0x69,0xd8,0x5a,0xf6,0x43,0xfd,0x1a,0x73,0x8,0xf9,0xc0,0x5f,0xef,0xda,0x17,0x4a,0x19,0xa5,0x97,0x4d,0x66,0x33,0x4c,0xfd,0x21,0x6a},
{0x35,0xb4,0x98,0x31,0xdb,0x41,0x15,0x70,0xea,0x1e,0xf,0xbb,0xed,0xcd,0x54,0x9b,0x9a,0xd0,0x63,0xa1,0x51,0x97,0x40,0x72,0xf6,0x75,0x9d,0xbf,0x91,0x47,0x6f,0xe2}};
/*the round function of E8 */
#define ROUND_FUNCTION(word,n,r)\
S_BOX(((word)[0]),((word)[2]),((word)[4]),((word)[6]),(LOAD(E8_bitslice_roundconstant[r]))) \
S_BOX(((word)[1]),((word)[3]),((word)[5]),((word)[7]),(LOAD(E8_bitslice_roundconstant[r]+16))) \
LIN_TRANS(word) \
PERMUTATION((word),n)
void E8(word128 *word){
int i;
for (i = 0; i < 42; i = i+7) {
ROUND_FUNCTION(word,0,i)
ROUND_FUNCTION(word,1,i+1)
ROUND_FUNCTION(word,2,i+2)
ROUND_FUNCTION(word,3,i+3)
ROUND_FUNCTION(word,4,i+4)
ROUND_FUNCTION(word,5,i+5)
ROUND_FUNCTION(word,6,i+6)
}
}
- описание используемых макросов см. в подразделах выше.
Исходные данные[править | править код]
Входной параметр[править | править код]
— длина хэша (число бит в выходном векторе хеш-функции).
Может принимать только следующие значения:
- 224, 256, 384 и 512;
- напомним, что данная статья, строго говоря, описывает семейство из 4-х хеш-функций.
Входное сообщение[править | править код]
Представляет собой число — длину сообщения и битовый вектор (если ). Даже если никаких трудностей для вычисления не возникает.




Алгоритм вычисления JH(M0)[править | править код]
1) Дополнение входного вектора
- Присоединение к сообщению дополнительных бит в конце. Происходит в три этапа:
- 1.1)Дополнение единицей.
- Присоединение к концу сообщения единичного бита.
- 1.2)Дополнение нулями.
- Присоединение к концу сообщения, дополненного единицей, нулевых бит в количестве штук.
- 1.3)Дополнение длиной сообщения.
- Присоединение к концу сообщения, дополненного единицей и нулями, 128 бит, в которых записана длина исходного сообщения (например, если , то добавка будет выглядеть так: ).
- В итоге получится дополненное сообщение с длиной, кратной .




2) Свёртка дополненного входного вектора функцией

- разбивается на блоки по бит. Обозначим за число таких блоков.

- Свёртка происходит за итераций. На -той итерации на вход поступает -й -битный блок сообщения и значение , вычисленное на предыдущей итерации. Имеется также нулевая итерация, на которой вычисляется из и . Таким образом имеем:
- .
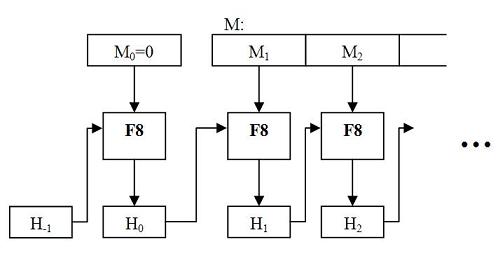
- и выбираются так: первые бит равны входному параметру — размеру выходного хэша (для , равных или это соответственно 0200h, 0180h, 0100h или 00e0h), а остальные биты и все биты задаются равными .










3) Выборка хэша из выхода функции
- Из -битного вектора , полученного на выходе на последней итерации свёртки дополненного входного сообщения, выбираются последние бит:



Криптоанализ[править | править код]
См. также[править | править код]
Примечания[править | править код]
- ↑ сравнение финалистов второго тура SHA по параметрам реализации на различных ПЛИС http://www.ecrypt.eu.org/hash2011/proceedings/hash2011_07.pdf Архивная копия от 23 августа 2011 на Wayback Machine
- ↑ алгоритм взят здесь: http://www3.ntu.edu.sg/home/wuhj/research/jh/jh_round3.pdf Архивная копия от 10 ноября 2011 на Wayback Machine
- ↑ Эти куски взяты по адресу http://www3.ntu.edu.sg/home/wuhj/research/jh/jh_sse2_opt64.h Архивная копия от 4 декабря 2011 на Wayback Machine и изменены для ясности и простоты.
- ↑ При использовании компилятора gcc для того, чтобы он подразумевал возможность использования дополнительных командных наборов, поддерживаемых процессором, типа SSE2, в командную строку при компиляции можно добавить опцию
-march=native(например"gcc -o prog prog.c -Wall -march=native").
Ссылки[править | править код]
- документация, актуальная в ноябре 2011 года
- http://www3.ntu.edu.sg/home/wuhj/research/jh/jh_round3.pdf Архивная копия от 10 ноября 2011 на Wayback Machine
- варианты исходных кодов на VHDL моделей электронных устройств, реализующих JH:
- варианты исходных кодов на C, реализующих JH:
- http://www3.ntu.edu.sg/home/wuhj/research/jh/jh_ref.h Архивная копия от 4 ноября 2011 на Wayback Machine
- http://www3.ntu.edu.sg/home/wuhj/research/jh/jh_bitslice_ref64.h Архивная копия от 11 августа 2011 на Wayback Machine
- http://www3.ntu.edu.sg/home/wuhj/research/jh/jh_sse2_opt64.h Архивная копия от 4 декабря 2011 на Wayback Machine
- страница автора для поддержки JH
- http://www3.ntu.edu.sg/home/wuhj/research/jh/index.html Архивная копия от 4 декабря 2011 на Wayback Machine
- ссылки на исследования криптоаналитиков и архивы файлов, отправлявшиеся на конкурс SHA-3
- ссылки на архивы с исходными кодами на VHDL (и сопутствующими файлами) моделей электронных устройств, реализующих алгоритмы хеш-функций, прошедших во второй тур SHA-3
- ссылки на исследования характеристик электронных устройств (реализованных на ПЛИС), реализующих алгоритмы хеш-функций, прошедших в финал второго тура SHA-3
| Общего назначения | |
|---|---|
| Криптографические | |
| Функции формирования ключа | |
| Контрольное число (сравнение) | |
| Применение хешей | |