Алгоритм поиска D*
Алгоритм поиска D* (произносится как «Ди стар») — это любой из трёх связанных алгоритмов инкрементного поиска:
- Оригинальный алгоритм D*[1] Энтони Стенца — это информированный алгоритм инкрементного поиска.
- Сфокусированный D*[2] — это алгоритм инкрементного эвристического поиска, разработанный Энтони Стенцем, который сочетает в себе идеи A*[3] и оригинального D*. Сфокусированный D* возник в результате дальнейшего развития оригинального D*.
- Облегчённый D*[4] — это алгоритм инкрементального эвристического поиска, созданный Свеном Кёнигом и Максимом Лихачёвым, который основан на LPA*[5], алгоритме инкрементального эвристического поиска, объединяющем идеи алгоритма поиска A* и динамического SWSF-FP[6].
Все три алгоритма поиска решают одни и те же основанные на предположениях планирования пути проблемы, включая планирование с предположением о свободном пространстве[7], когда робот должен перемещаться к заданным координатам цели на неизвестной местности. Он делает предположения о неизвестной части местности (например, что на ней нет препятствий) и находит кратчайший путь от её текущих координат до координат цели при этих предположениях. Затем робот следует по пути. Когда он наблюдает новую информацию на карте (например, ранее неизвестные препятствия), он добавляет эту информацию на свою карту и, при необходимости, перепланировывает новый кратчайший путь от текущих координат к заданным координатам цели. Он повторяет процесс до тех пор, пока не достигнет координат цели или не определит, что координаты цели не могут быть достигнуты. При пересечении неизвестной местности могут часто обнаруживаться новые препятствия, поэтому это перепланирование должно быть быстрым. Инкрементальные (эвристические) алгоритмы поиска ускоряют поиск последовательностей похожих поисковых задач, используя опыт решения предыдущих проблем для ускорения поиска текущей. Если предположить, что координаты цели не меняются, все три алгоритма поиска более эффективны, чем повторные поиски A*.
D* и его варианты широко использовались для мобильного робота и автономного транспортного средства навигации. Современные системы обычно основаны на облегчённом, а не на оригинальном или сфокусированном D*. Фактически, даже лаборатория Стенца в некоторых реализациях использует облегчённый, а не оригинальный D*[8]. Такие навигационные системы включают в себя прототип системы, испытанный на марсоходах Opportunity и Spirit, и навигационную систему победителя конкурса DARPA Urban Challenge, оба разработанные в Университете Карнеги — Меллона.
Оригинальный D* был представлен Энтони Стенцем в 1994 году. Название D* происходит от термина «Dynamic A*» (рус. «Динамический A*»), потому что алгоритм ведёт себя как A*[2], за исключением того, что стоимость дуги может изменяться по мере выполнения алгоритма.
Операции[править | править код]
Основные операции D* описаны ниже.
Подобно алгоритму Дейкстры и A*, D* поддерживает список узлов для оценки, известный как ОТКРЫТЫЙ список. Узлы помечаются как имеющие одно из нескольких состояний:
- НОВЫЙ, означает, что он никогда не помещался в ОТКРЫТЫЙ список.
- ОТКРЫТЫЙ, означает, что он в настоящее время находится в ОТКРЫТОМ списке.
- ЗАКРЫТЫЙ, означает, что его больше нет в ОТКРЫТОМ списке.
- ПОДНЯТЫЙ, указывает на то, что его стоимость выше, чем в последний раз, когда он был в ОТКРЫТОМ списке.
- НИЖНИЙ, указывает на то, что его стоимость ниже, чем в последний раз, когда он был в ОТКРЫТОМ списке.
Расширение[править | править код]
Алгоритм работает путём итеративного выбора узла из ОТКРЫТОГО списка и его оценки. Затем он распространяет изменения узла на все соседние узлы и помещает их в ОТКРЫТЫЙ список. Этот процесс распространения называется «расширением». В отличие от канонического A*, который следует по пути от начала до конца, D* начинает поиск в обратном направлении от целевого узла. Каждый расширенный узел имеет обратный указатель, который относится к следующему узлу, ведущему к цели, и каждый узел знает точную стоимость для цели. Когда начальный узел является следующим расширяемым узлом, алгоритм выполнен, и путь к цели можно найти, просто следуя обратным указателям.
-
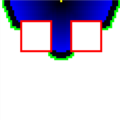 Расширение в процессе. Финишный узел (жёлтый) находится в середине верхнего ряда точек, начальный узел находится в середине нижнего ряда. Красный указывает на препятствие; чёрный/синий обозначает расширенные узлы (яркость обозначает стоимость). Зелёным обозначены узлы, которые расширяются.
Расширение в процессе. Финишный узел (жёлтый) находится в середине верхнего ряда точек, начальный узел находится в середине нижнего ряда. Красный указывает на препятствие; чёрный/синий обозначает расширенные узлы (яркость обозначает стоимость). Зелёным обозначены узлы, которые расширяются. -
 Расширение завершено. Путь указан голубым цветом.
Расширение завершено. Путь указан голубым цветом.


Преодоление препятствий[править | править код]
Когда на заданном пути обнаруживается препятствие, все затронутые точки снова помещаются в ОТКРЫТЫЙ список, на этот раз с пометкой ПОДНЯТЫЙ. Однако перед увеличением стоимости ПОДНЯТОГО узла алгоритм проверяет его соседей и исследует, может ли он снизить стоимость узла. В противном случае состояние ПОДНЯТЫЙ распространяется на всех потомков узлов, то есть узлы, на которые есть обратные указатели. Затем эти узлы оцениваются, и состояние ПОДНЯТЫЙ передаётся, формируя волну. Когда ПОДНЯТЫЙ узел может быть уменьшен, его обратный указатель обновляется и передаёт состояние НИЖНИЙ своим соседям. Эти волны состояний ПОДНЯТЫЙ и НИЖНИЙ являются сердцем D*.
К этому моменту волны не могут коснуться целого ряда других точек. Следовательно, алгоритм работал только с точками, на которые влияет изменение стоимости.
-
 Препятствие добавлено (красный) и узлы отмечены как ПОДНЯТЫЕ (жёлтый).
Препятствие добавлено (красный) и узлы отмечены как ПОДНЯТЫЕ (жёлтый). -
 Расширение в процессе. Жёлтым цветом обозначены узлы, отмеченные как ПОДНЯТЫЕ, зелёным — узлы, отмеченные как НИЖНИЕ.
Расширение в процессе. Жёлтым цветом обозначены узлы, отмеченные как ПОДНЯТЫЕ, зелёным — узлы, отмеченные как НИЖНИЕ.


Ещё один тупик[править | править код]
На этот раз невозможно так элегантно выйти из тупика. Ни одна из точек не может найти новый маршрут через соседа к пункту назначения. Поэтому они продолжают распространять своё повышение стоимости. Можно найти только точки за пределами канала, которые могут привести к месту назначения по жизнеспособному маршруту. Так развиваются две НИЖНИЕ волны, которые расширяются в виде точек, отмеченных как недостижимые с новой информацией о маршруте.
-
 Канал заблокирован дополнительными препятствиями (красный).
Канал заблокирован дополнительными препятствиями (красный). -
 Расширение в процессе. ПОДНЯТАЯ волна (жёлтый), НИЖНЯЯ волна (зелёный).
Расширение в процессе. ПОДНЯТАЯ волна (жёлтый), НИЖНЯЯ волна (зелёный). -
 Найден НОВЫЙ путь (голубой).
Найден НОВЫЙ путь (голубой).



Псевдокод[править | править код]
while (!openList.isEmpty()) {
point = openList.getFirst();
expand(point);
}
Развернуть[править | править код]
void expand(currentPoint) {
boolean isRaise = isRaise(currentPoint);
double cost;
for each (neighbor in currentPoint.getNeighbors()) {
if (isRaise) {
if (neighbor.nextPoint == currentPoint) {
neighbor.setNextPointAndUpdateCost(currentPoint);
openList.add(neighbor);
} else {
cost = neighbor.calculateCostVia(currentPoint);
if (cost < neighbor.getCost()) {
currentPoint.setMinimumCostToCurrentCost();
openList.add(currentPoint);
}
}
} else {
cost = neighbor.calculateCostVia(currentPoint);
if (cost < neighbor.getCost()) {
neighbor.setNextPointAndUpdateCost(currentPoint);
openList.add(neighbor);
}
}
}
}
Проверить на поднятие[править | править код]
boolean isRaise(point) {
double cost;
if (point.getCurrentCost() > point.getMinimumCost()) {
for each(neighbor in point.getNeighbors()) {
cost = point.calculateCostVia(neighbor);
if (cost < point.getCurrentCost()) {
point.setNextPointAndUpdateCost(neighbor);
}
}
}
return point.getCurrentCost() > point.getMinimumCost();
}
Варианты[править | править код]
Сфокусированный D*[править | править код]
Как следует из названия, сфокусированный D* является расширением D*, которое использует эвристику, чтобы сфокусировать распространение ПОДНЯТОГО и НИЖНЕГО в направлении робота. Таким образом, обновляются только важные состояния, так же как A* вычисляет затраты только для некоторых узлов.
Облегчённый D*[править | править код]
Облегчённый D* не основан на исходном или сфокусированном D*, но реализует то же поведение. Это проще для понимания и может быть реализовано меньшим количеством строк кода, отсюда и название «Облегчённый D*». По производительности он не хуже сфокусированного D*. Облегчённый D* основан на LPA*[5], который был представлен Кёнигом и Лихачёвым несколькими годами ранее. Облегчённый D*
Минимальная стоимость по сравнению с текущей стоимостью[править | править код]
Для D* важно различать текущие и минимальные затраты. Первые важны только во время сбора, а последние решающие, потому что они сортируют ОТКРЫТЫЙ список. Функция, которая возвращает минимальную стоимость, всегда является наименьшей стоимостью для текущей точки, поскольку это первая запись в ОТКРЫТОМ списке.
Примечания[править | править код]
- ↑ Энтони Стенц (1994). "Оптимальное и эффективное планирование пути для частично известных сред". Материалы Международной конференции по робототехнике и автоматизации: 3310—3317. CiteSeerX 10.1.1.15.3683.
- ↑ 1 2 Э. Стенц (1995). "Сфокусированный алгоритм D* для перепланирования в реальном времени". Материалы Международной совместной конференции по искусственному интеллекту: 1652—1659. CiteSeerX 10.1.1.41.8257.
- ↑ Питер Эллиот Харт, Нильс Джон Нильссон, Бертрам Рафаэль (1968). "Формальная основа для эвристического определения путей минимальной стоимости". Транзакции IEEE по системной науке и кибернетике. SSC-4 (2): 100—107. doi:10.1109/TSSC.1968.300136.
{{cite journal}}: Википедия:Обслуживание CS1 (множественные имена: authors list) (ссылка) - ↑ Свен Кёниг, Максим Лихачёв (2005). "Быстрое перепланирование навигации в неизвестной местности". Транзакции по робототехнике. 21 (3): 354—363. CiteSeerX 10.1.1.65.5979. doi:10.1109/tro.2004.838026.
- ↑ 1 2 Свен Кёниг, Максим Лихачёв, Дэвид Фёрси (2004). "Пожизненное планирование A*". Искусственный интеллект. 155 (1—2): 93—146. doi:10.1016/j.artint.2003.12.001.
{{cite journal}}: Википедия:Обслуживание CS1 (множественные имена: authors list) (ссылка) - ↑ Г. Рамалингам, Томас В. Репс (1996). "Инкрементальный алгоритм обобщения задачи поиска кратчайшего пути". Журнал алгоритмов. 21 (2): 267—305. CiteSeerX 10.1.1.3.7926. doi:10.1006/jagm.1996.0046.
- ↑ Свен Кёниг, Юрий Смирнов, Крейг Тови (2003). "Границы производительности для планирования на неизвестной местности". Искусственный интеллект. 147 (1—2): 253—279. doi:10.1016/s0004-3702(03)00062-6.
{{cite journal}}: Википедия:Обслуживание CS1 (множественные имена: authors list) (ссылка) - ↑ D. Wooden (2006). Планирование пути для мобильных роботов на основе графов (Thesis). Технологический институт Джорджии.
